【2026年7月】生成 AI モデルを比較 (Claude, GPT, Gemini, Grok, DeepSeek, Kimi, GLM, Mistral)
OpenRouter は、Claude、GPT、Gemini といったクローズドなモデルや中国発の オープンウェイトモデルまで、いろんなAIを切り替えて使える。とはいえ「結局どれを選べばいいのか」 と悩みがちなので、今回は主要モデルの値段と実力をざっくり比較してみた。
そもそも「オープン」と「クローズド」とは
- クローズド: Claude・GPT・Gemini・Grok のように、モデルの中身(重み)が公開されていないもの。 会社のサーバー経由でしか使えない。
- オープンウェイト: DeepSeek・Kimi・GLM・Mistral のように、モデルの中身が公開されていて、 誰でも自分のPCやクラウドで動かせるもの。
階級別の値段
まずは最重量の値段から。
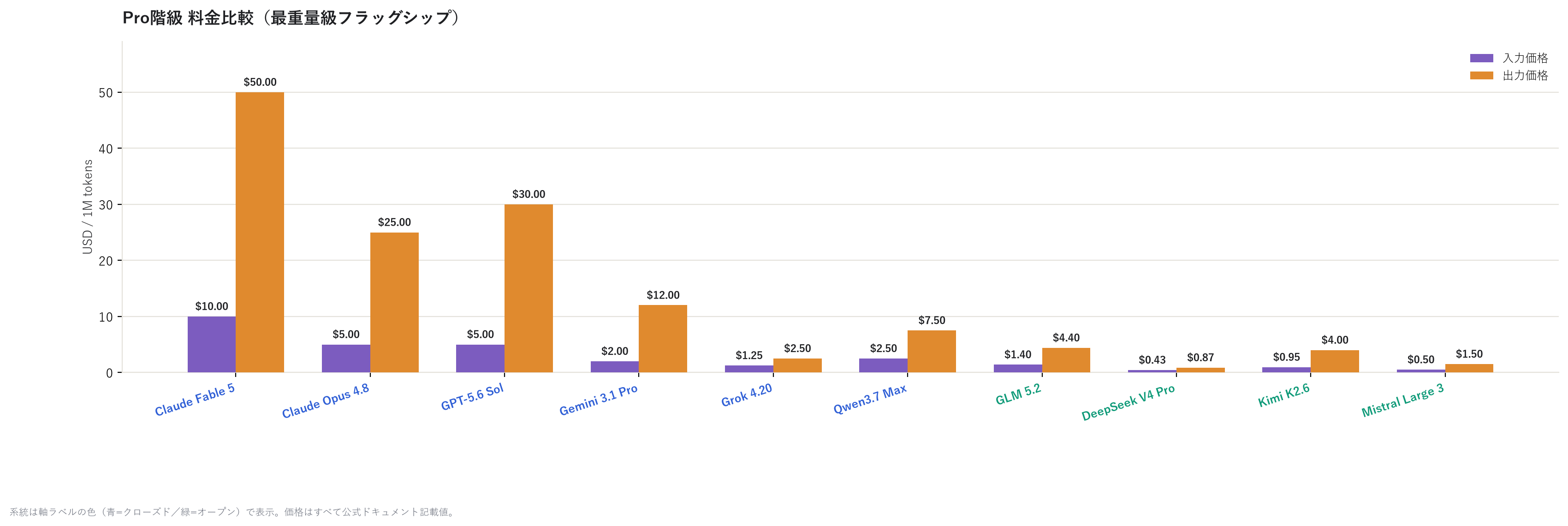
見ての通り、Claude Fable 5 が圧倒的に高い(出力 $50/1Mトークン)一方、DeepSeek V4 Pro は 出力たったの $0.87。同じ「Pro」を名乗っていても、値段の差は50倍以上ある。オープン勢 (緑色のラベル)が軒並み安いのが一目瞭然だ。
中小量級も見てみる。
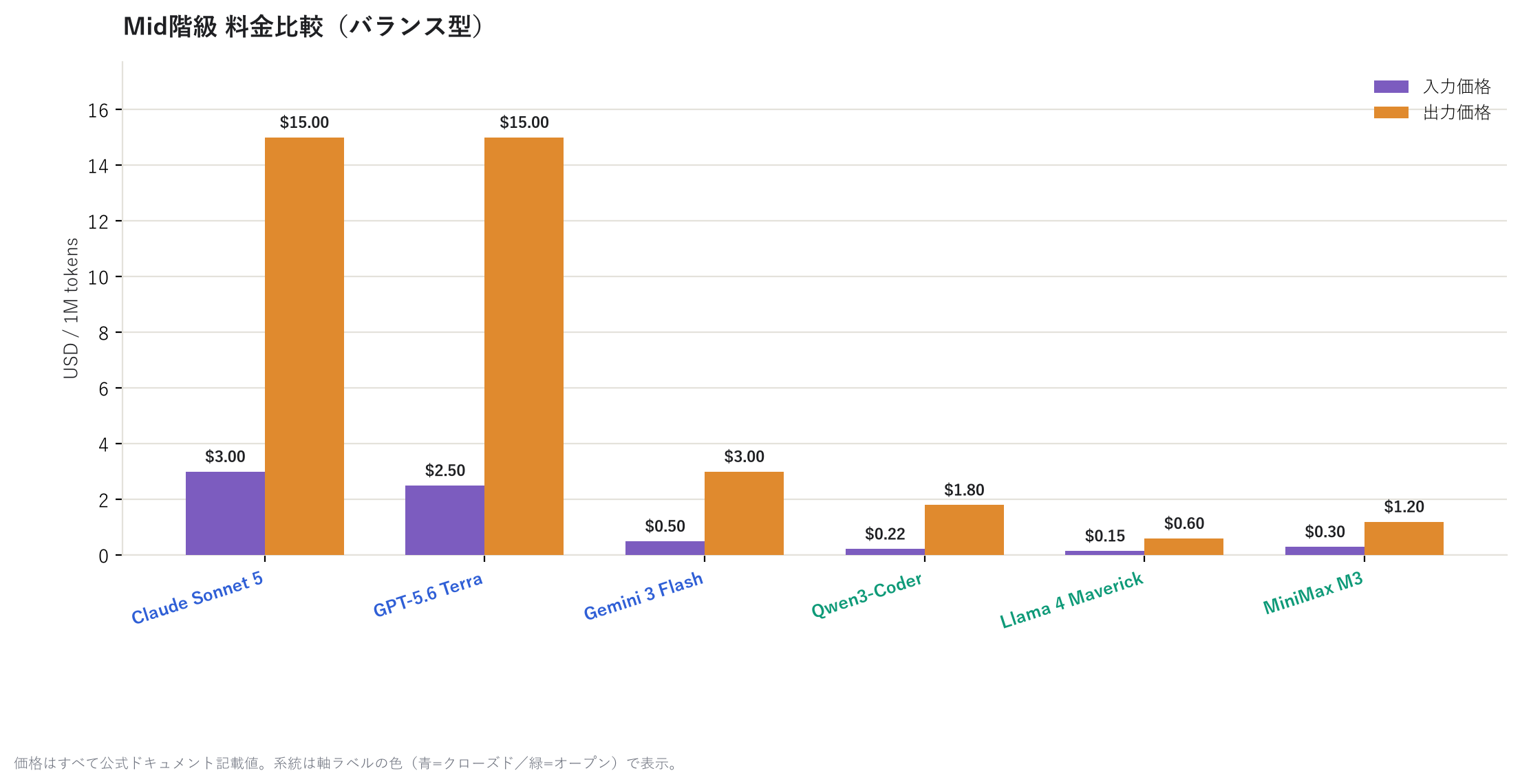
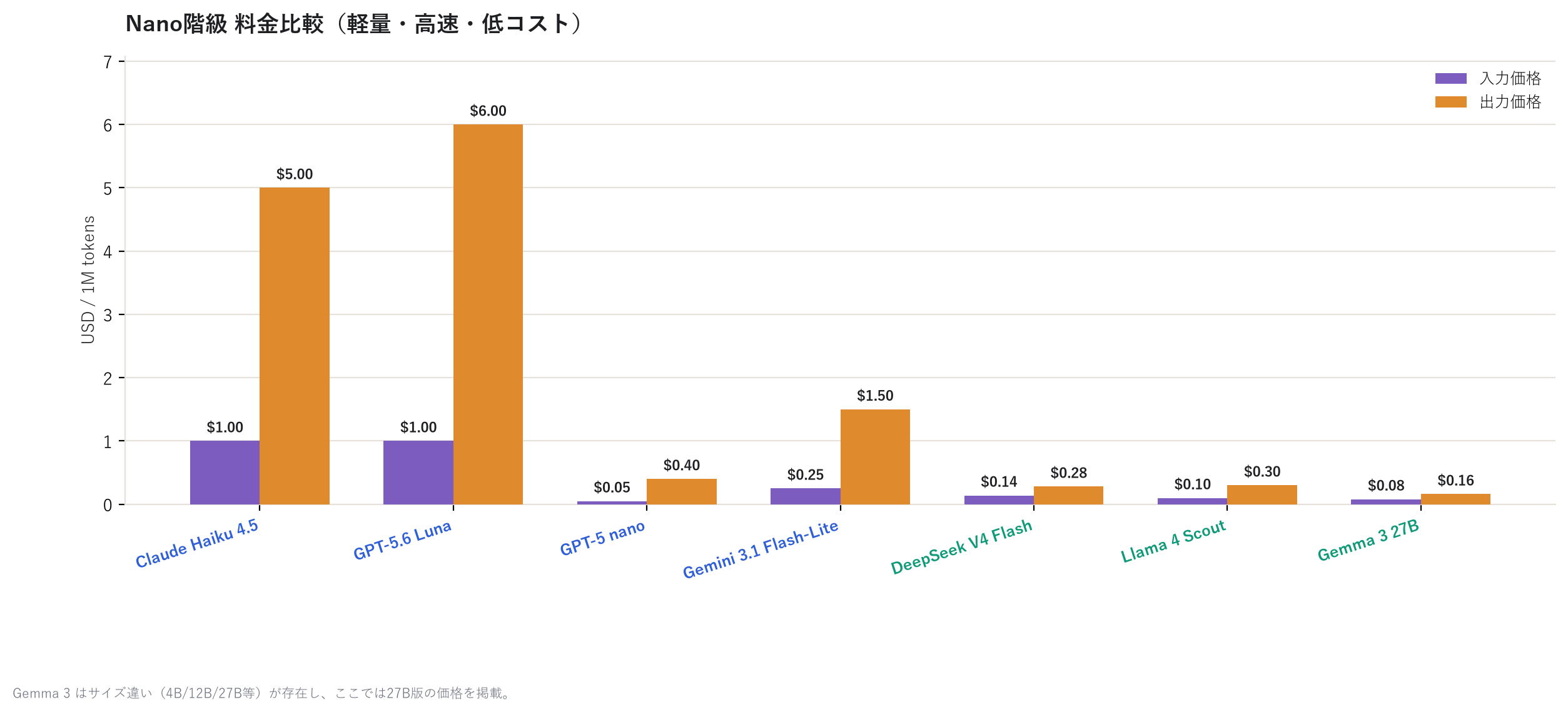
小量級になると、GPT-5 nano は出力 $0.40 とほぼ「使い放題」レベルの安さだ。ちょっとした 分類作業や下書き生成なら、この階級で十分なことも多い。
コスパを見てみる
値段だけ見ると「安いモデルは性能も低いのでは」と思いがちだが、実はそうでもない。 階級を分けずに、価格とIntelligence Indexのスコアがそろっているモデル20個を1枚にまとめてみる。 GPT・Gemini・Qwen・Llama・Gemma・Mistralなど、オープン/クローズド問わずできるだけ多くの モデルを含めた。
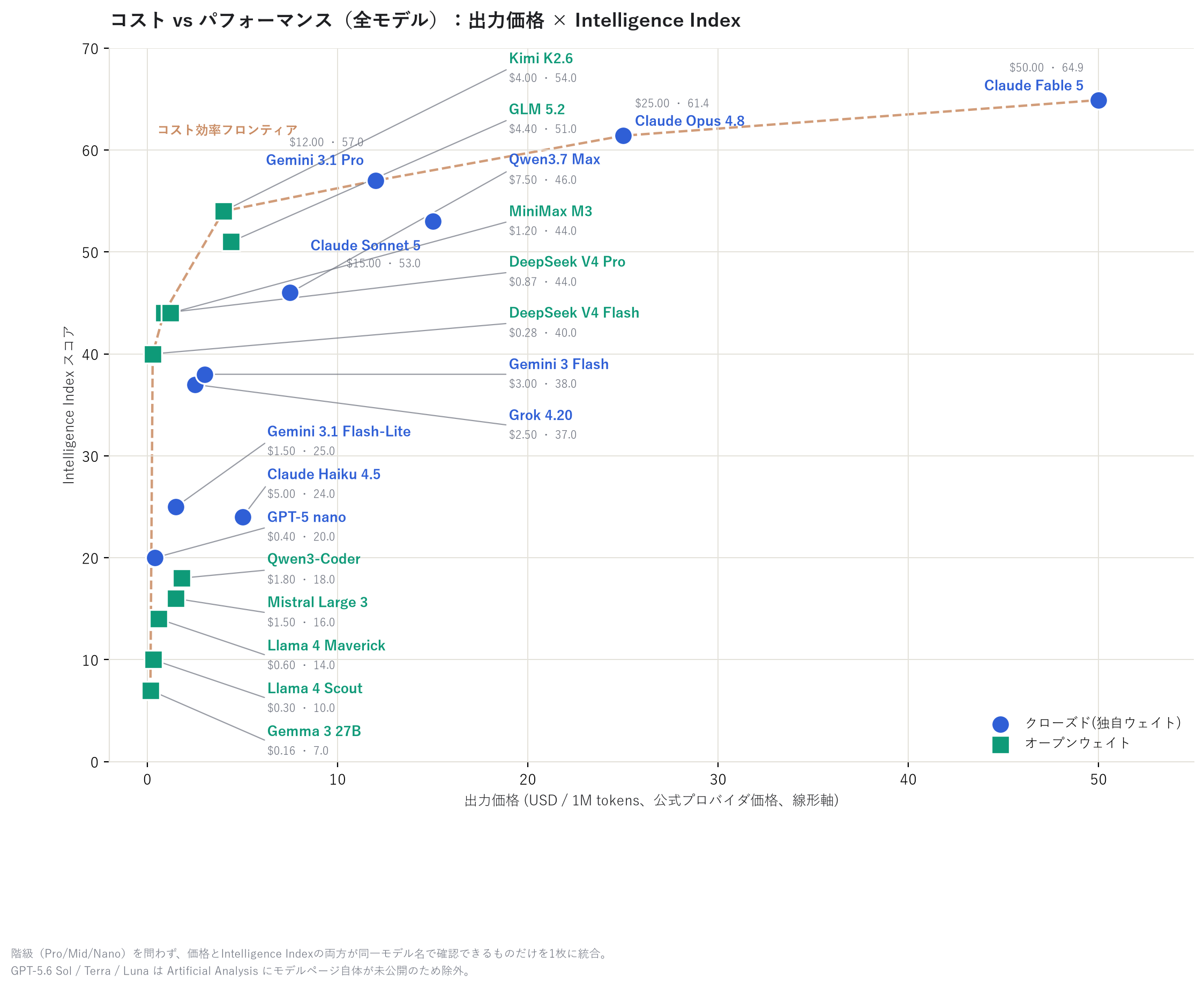
縦軸は「Intelligence Index」という総合力スコア(詳しくは後述)。点線で結んだ「コスパの良い ライン」は Gemma 3 27B → DeepSeek V4 Flash → DeepSeek V4 Pro → Kimi K2.6 → Gemini 3.1 Pro → Claude Opus 4.8 → Claude Fable 5 という、Nano・Mid・Proの階級をまたいだ 7モデルで形成されている。DeepSeek V4 Pro はわずか出力$0.87でGemini 3.1 Pro($12.00)に迫る スコアを出しており、実質的なコスパの起点として頭ひとつ抜けている。一方、フロンティアの内側に ある Qwen3.7 Max・MiniMax M3・GLM 5.2・Claude Sonnet 5・Gemini 3 Flash・Grok 4.20・ Claude Haiku 4.5・Gemini 3.1 Flash-Lite・Qwen3-Coder・Mistral Large 3・Llama 4 Maverick・ Llama 4 Scout などは「同じくらいの価格帯の他モデルより実力で見劣りする」ポジションだ。
コスパ重視なら、まずは一番安いところから試してみるのもアリだろう。
結局どのモデルが一番賢いのか
総合力とコーディング力のランキングも見てみる。
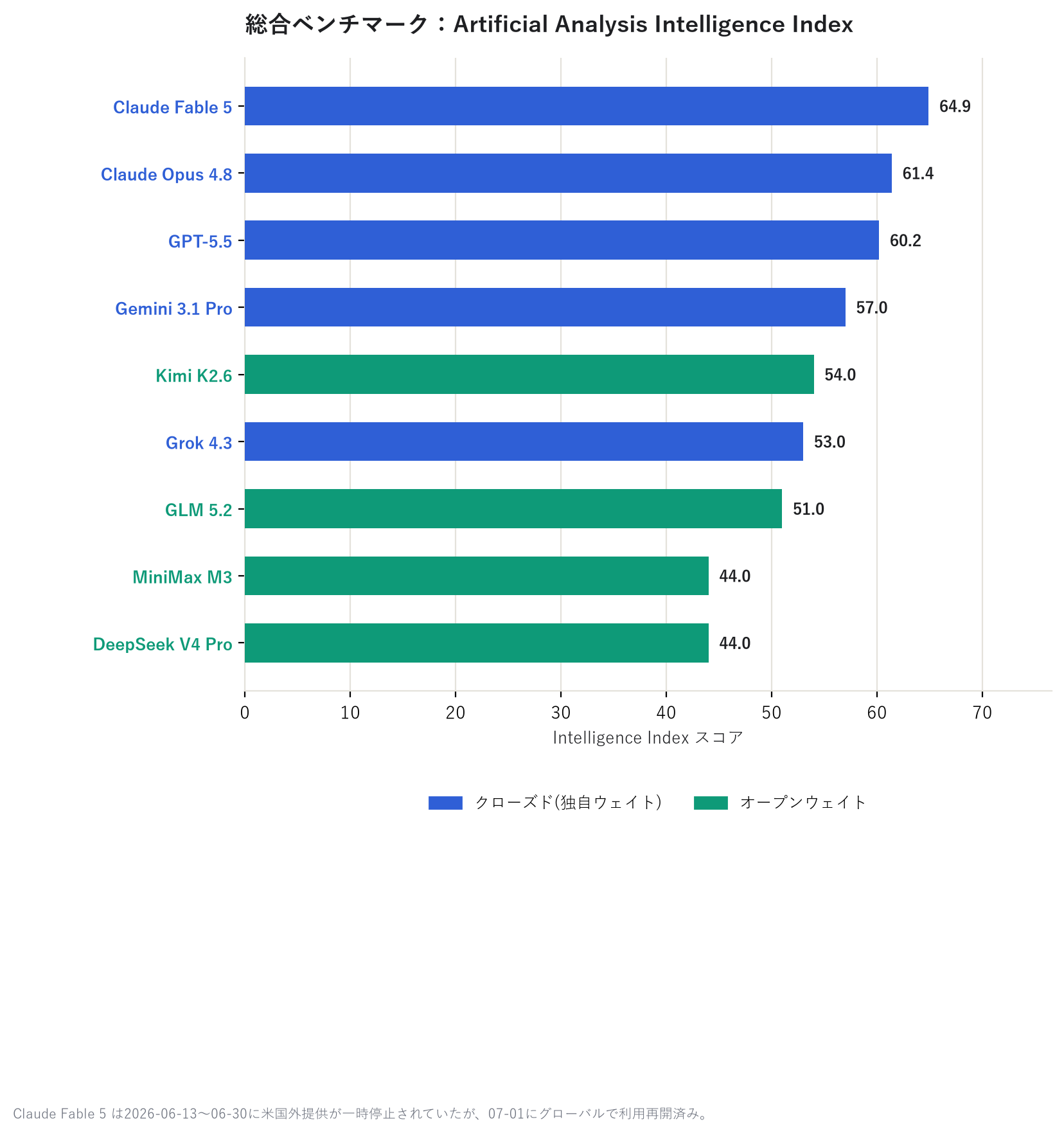
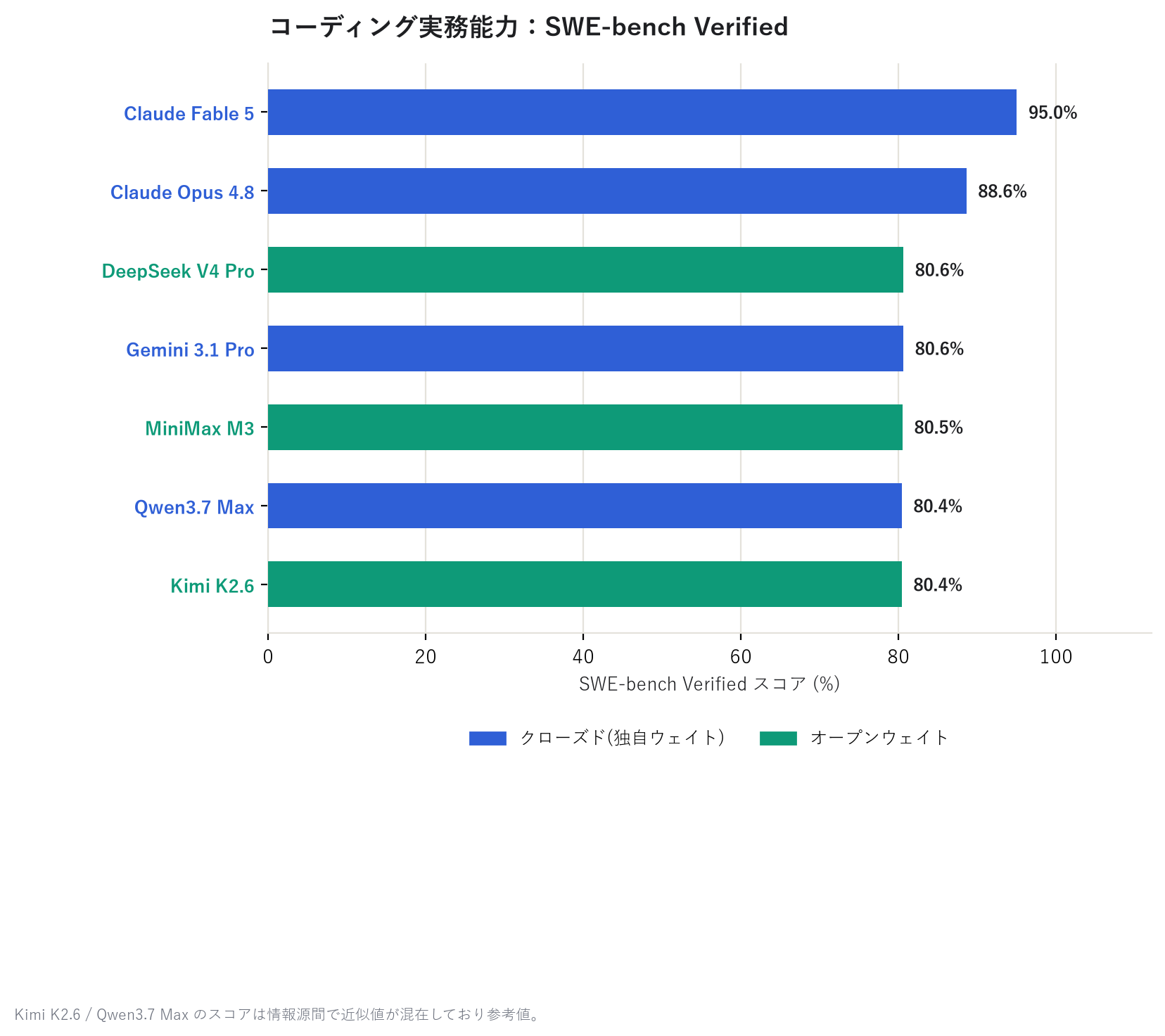
1枚目の「総合力」は Artificial Analysis Intelligence Index という第三者ベンチマーク団体の スコア、2枚目の「コーディング力」は SWE-bench Verified という、実在するソフトウェアの バグ修正課題をどれだけ解けるかを測るテストのスコアだ。どちらも各モデル会社の自己申告ではなく、 外部の評価サイトが計測・公表している数値である。
総合力では Claude Fable 5 がGPT-5.5に約5ポイント差をつけてトップ、僅差で Claude Opus 4.8・ GPT-5.5・Gemini 3.1 Pro が続く。コーディングに限っても Claude Fable 5 が頭ひとつ抜けて95% というスコアだ。そのすぐ下に、オープン系の DeepSeek V4 Pro がクローズド勢と肩を並べているのも 面白いポイントである。
おまけ:オープンモデルの「中身の大きさ」
オープンウェイトモデルは中身が公開されているので、パラメータ数(モデルの大きさ)も分かる。 バーの濃い緑が実際に推論で使われる「活性化パラメータ」、薄い緑がMoE(Mixture of Experts)構成上 その時使われていない残りのエキスパート分だ。
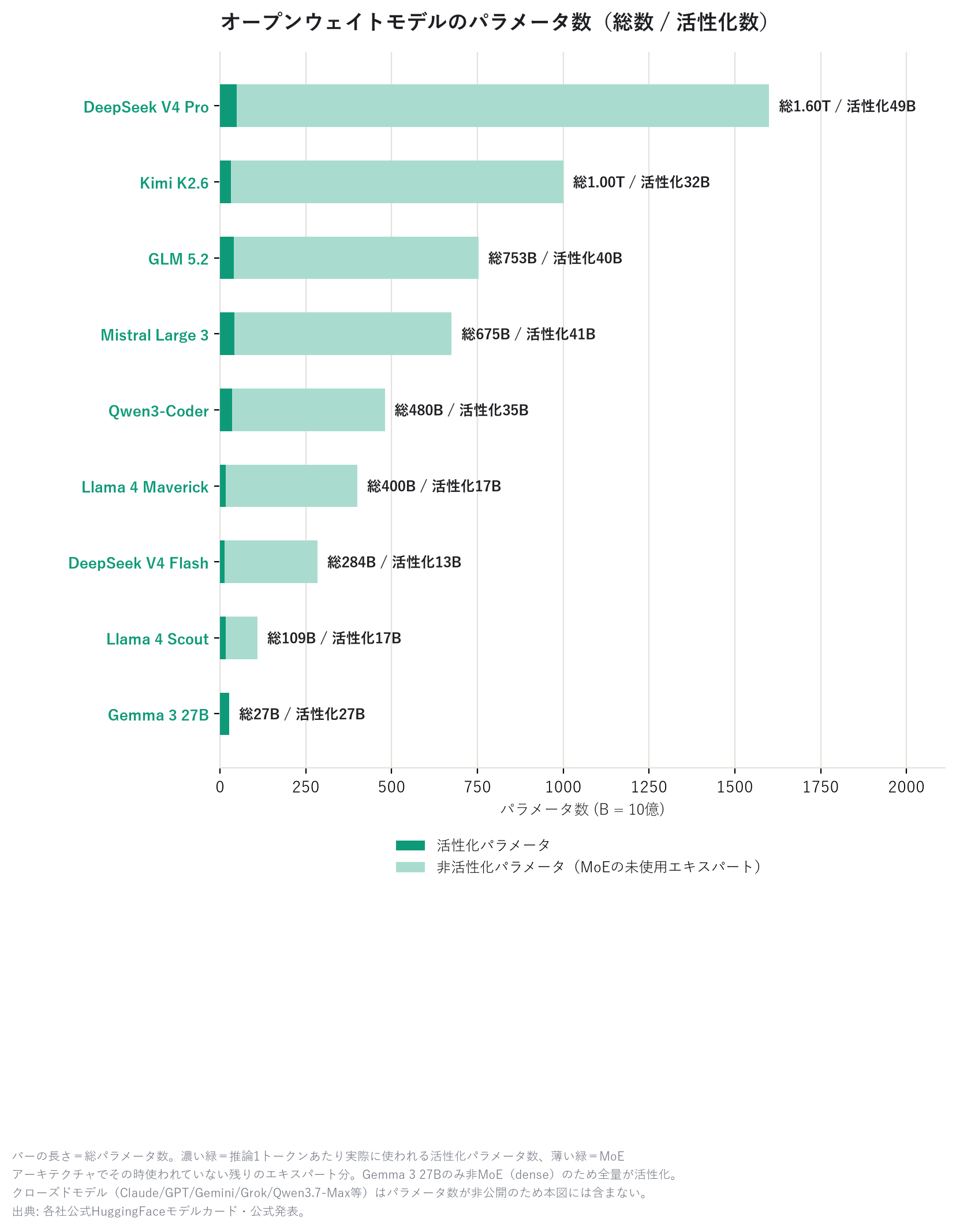
DeepSeek V4 Pro が総1.6兆パラメータで一番大きいが、実際に動くときに使うのは そのうち490億だけ(MoEという仕組みのおかげ)。大きい割に軽快に動く、というのがポイントだ。 図中で唯一 Gemma 3 27Bだけはバーが全部濃い緑になっているが、これはMoEではなく 全パラメータを毎回使う「dense」構成だから。デンスモデルは総数=活性化数になるため、 MoE勢とは大きさの比較の意味合いが少し異なる点に注意。
まとめ:どれを選べばいいか
- とにかく一番賢いのが欲しい → Claude Fable 5 か Claude Opus 4.8(値段は覚悟)
- コスパ重視、コーディングもさせたい → DeepSeek V4 Pro(激安なのにかなり優秀)
- 普段使いのバランス型 → Claude Sonnet 5 や Gemini 3 Flash
- とにかく安く大量にさばきたい → GPT-5 nano や DeepSeek V4 Flash
値段もランキングも動きが早い世界なので、実際に使う前には openrouter.ai/models で最新情報を確認することを忘れずに。
スコアの情報元
本記事で使ったベンチマークスコアの出典は以下の通り。いずれもモデル提供元とは独立した 第三者の評価サイトが計測・公表している数値である。
- 総合力(Intelligence Index): Artificial Analysis
- コーディング力(SWE-bench Verified): SWE-bench Leaderboards(公式)
なお Kimi K2.6 / Qwen3.7 Max の SWE-bench Verified スコアは、情報源間で近似値が混在しており 参考値として扱っている。
読み込み中...