[July 2026] Comparing Generative AI Models (Claude, GPT, Gemini, Grok, DeepSeek, Kimi, GLM, Mistral)
OpenRouter lets you switch between all sorts of AIs, from closed models like Claude, GPT, and Gemini to open-weight models coming out of China. Even so, it's easy to get stuck on "which one should I actually pick?", so this time I did a rough comparison of the price and performance of the major models.
What do "open" and "closed" even mean here
- Closed: Models like Claude, GPT, Gemini, and Grok, where the internals (weights) aren't published. You can only use them through the company's servers.
- Open-weight: Models like DeepSeek, Kimi, GLM, and Mistral, where the internals are published, so anyone can run them on their own PC or cloud.
Pricing by weight class
Let's start with pricing for the heaviest class.
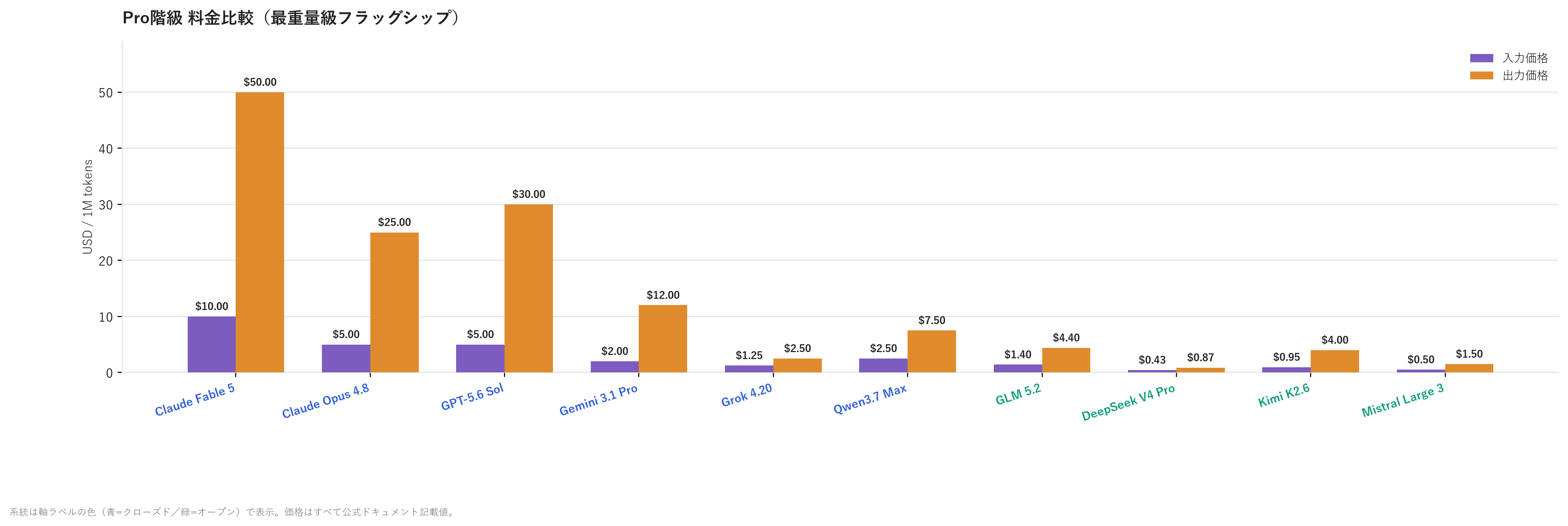
As you can see, Claude Fable 5 is overwhelmingly expensive (output $50/1M tokens), while DeepSeek V4 Pro's output is just $0.87. Even though both are labeled "Pro," the price gap is more than 50x. It's immediately obvious that the open camp (green labels) is cheaper across the board.
Let's also look at the mid and light classes.
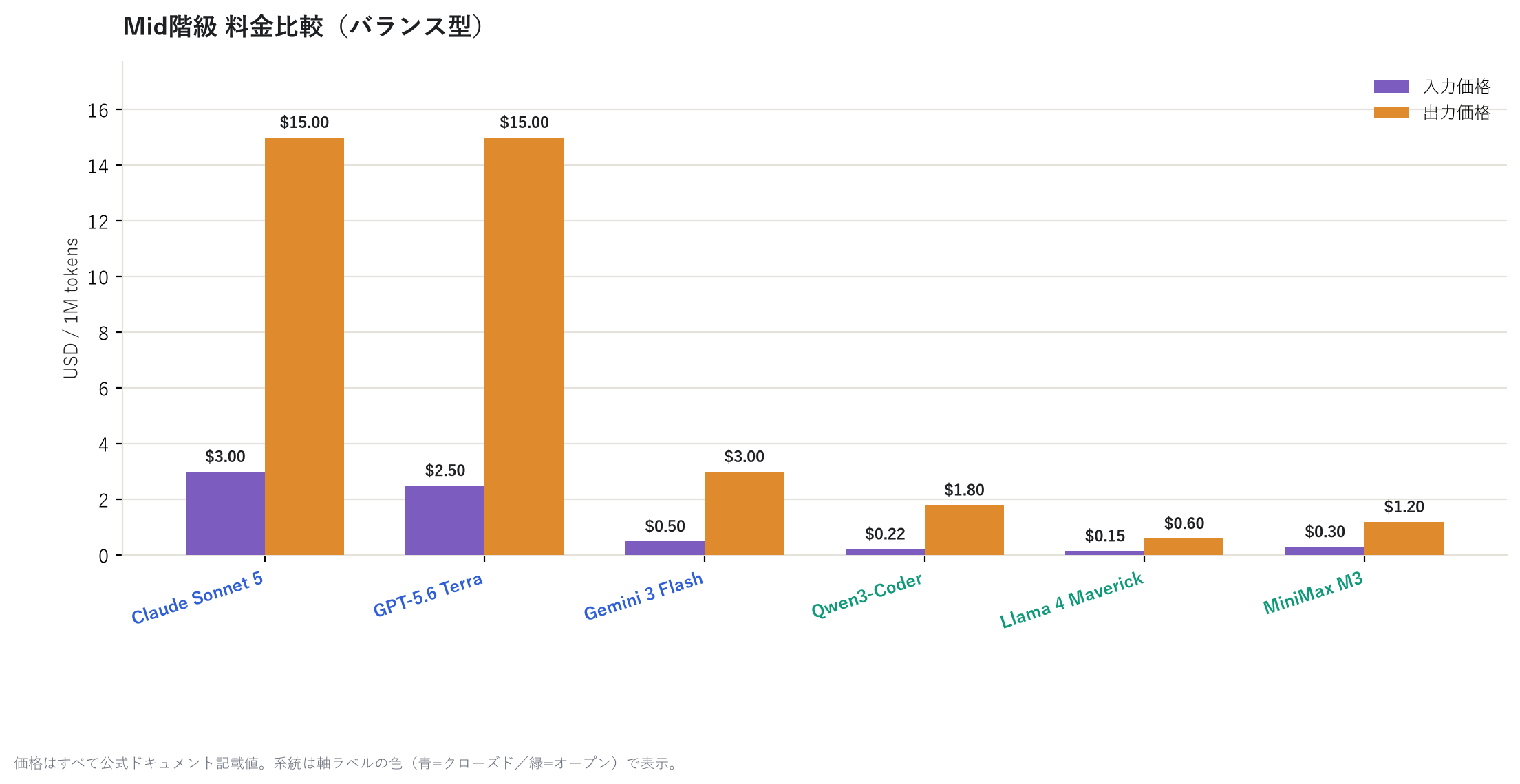
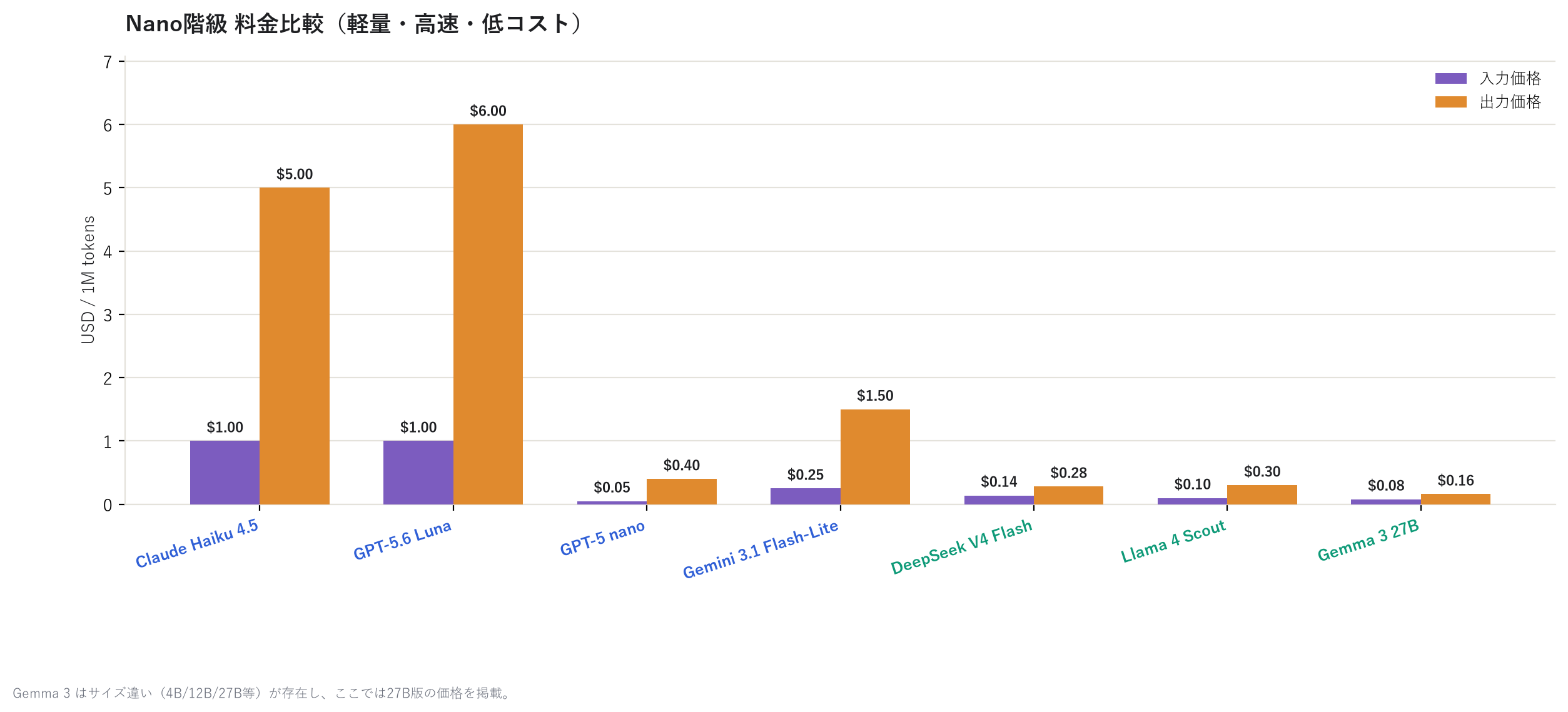
Down at the light class, GPT-5 nano comes in at $0.40 for output — practically "unlimited use" territory. For simple classification tasks or draft generation, this class is often more than enough.
Looking at cost-performance
Just looking at price, you might assume "the cheap models must be weaker too" — but that's not really the case. Ignoring weight classes for a moment, here's a single chart combining 20 models that have both pricing and Intelligence Index scores available. I tried to include as many models as possible, open and closed alike, across GPT, Gemini, Qwen, Llama, Gemma, Mistral, and more.
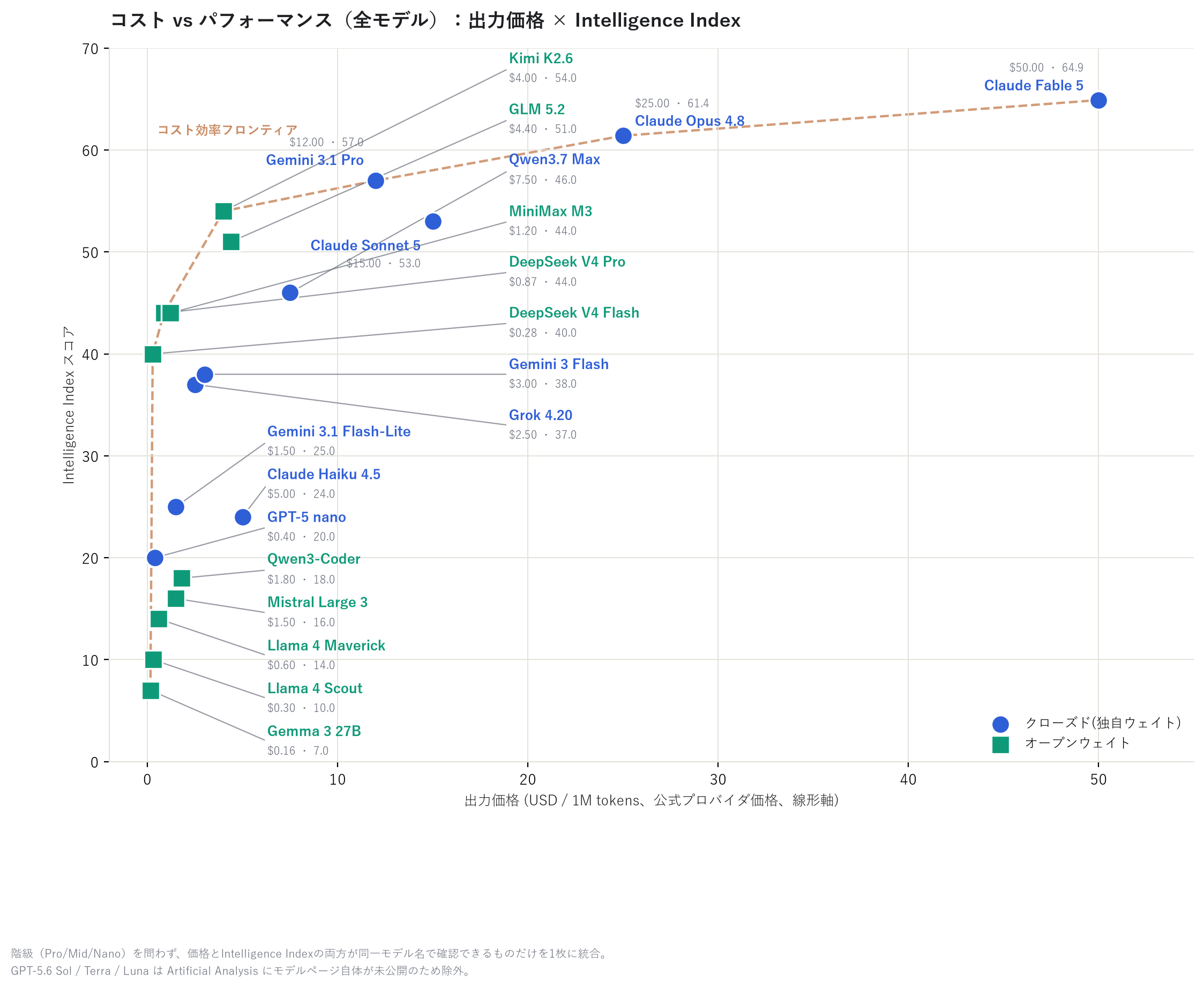
The vertical axis is the "Intelligence Index," an overall capability score (more on this later). The dotted "cost-performance frontier" line is formed by seven models spanning the Nano, Mid, and Pro classes: Gemma 3 27B → DeepSeek V4 Flash → DeepSeek V4 Pro → Kimi K2.6 → Gemini 3.1 Pro → Claude Opus 4.8 → Claude Fable 5. DeepSeek V4 Pro, at just $0.87 for output, comes close to matching Gemini 3.1 Pro's ($12.00) score, putting it a clear step ahead as the effective starting point for cost-efficiency. Meanwhile, models sitting inside the frontier — Qwen3.7 Max, MiniMax M3, GLM 5.2, Claude Sonnet 5, Gemini 3 Flash, Grok 4.20, Claude Haiku 4.5, Gemini 3.1 Flash-Lite, Qwen3-Coder, Mistral Large 3, Llama 4 Maverick, and Llama 4 Scout — all underperform relative to other models in their price range.
If cost-efficiency is your priority, it's worth starting from the cheapest end of the frontier.
So which model is actually the smartest
Let's also look at the rankings for overall capability and coding ability.
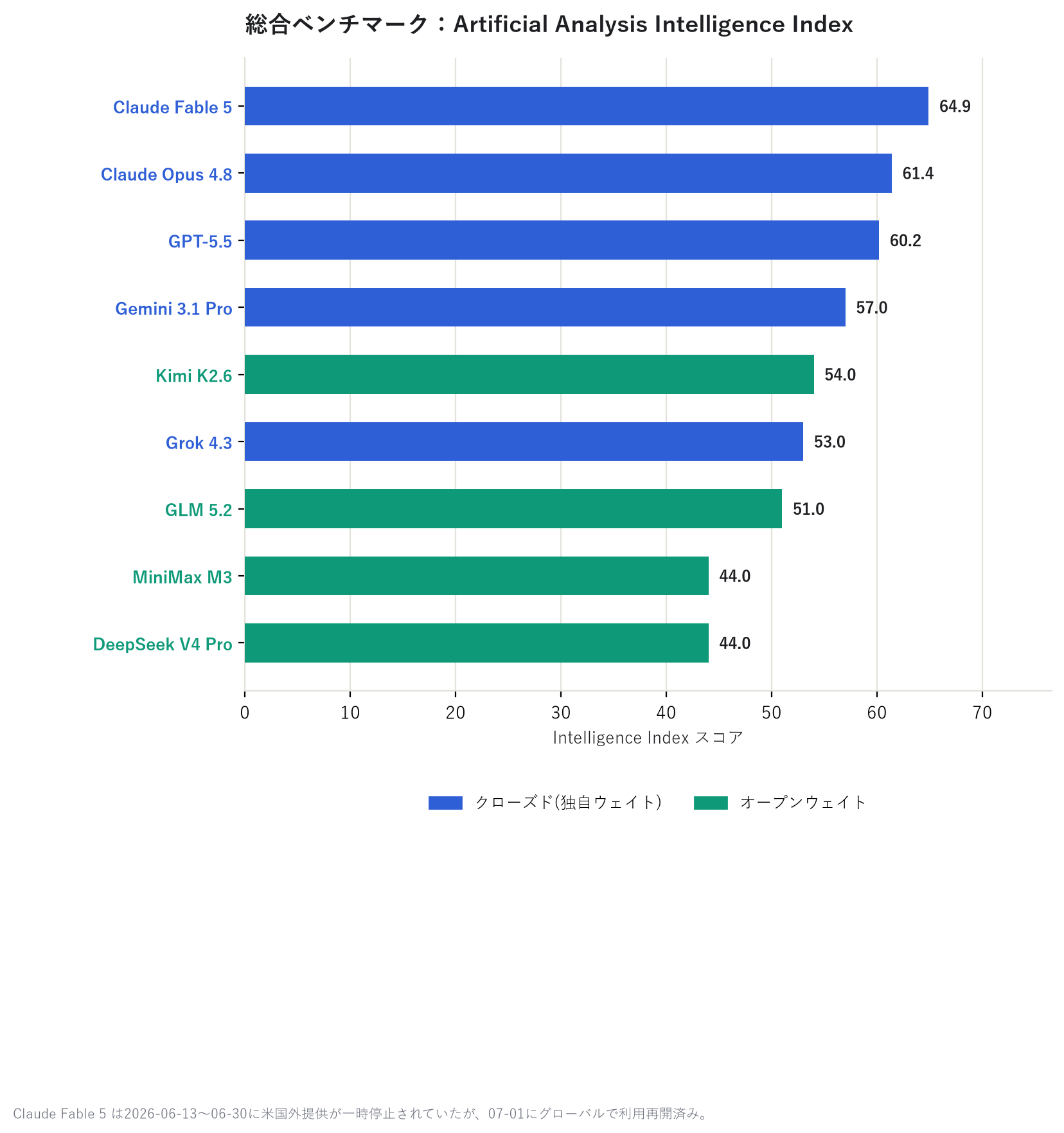
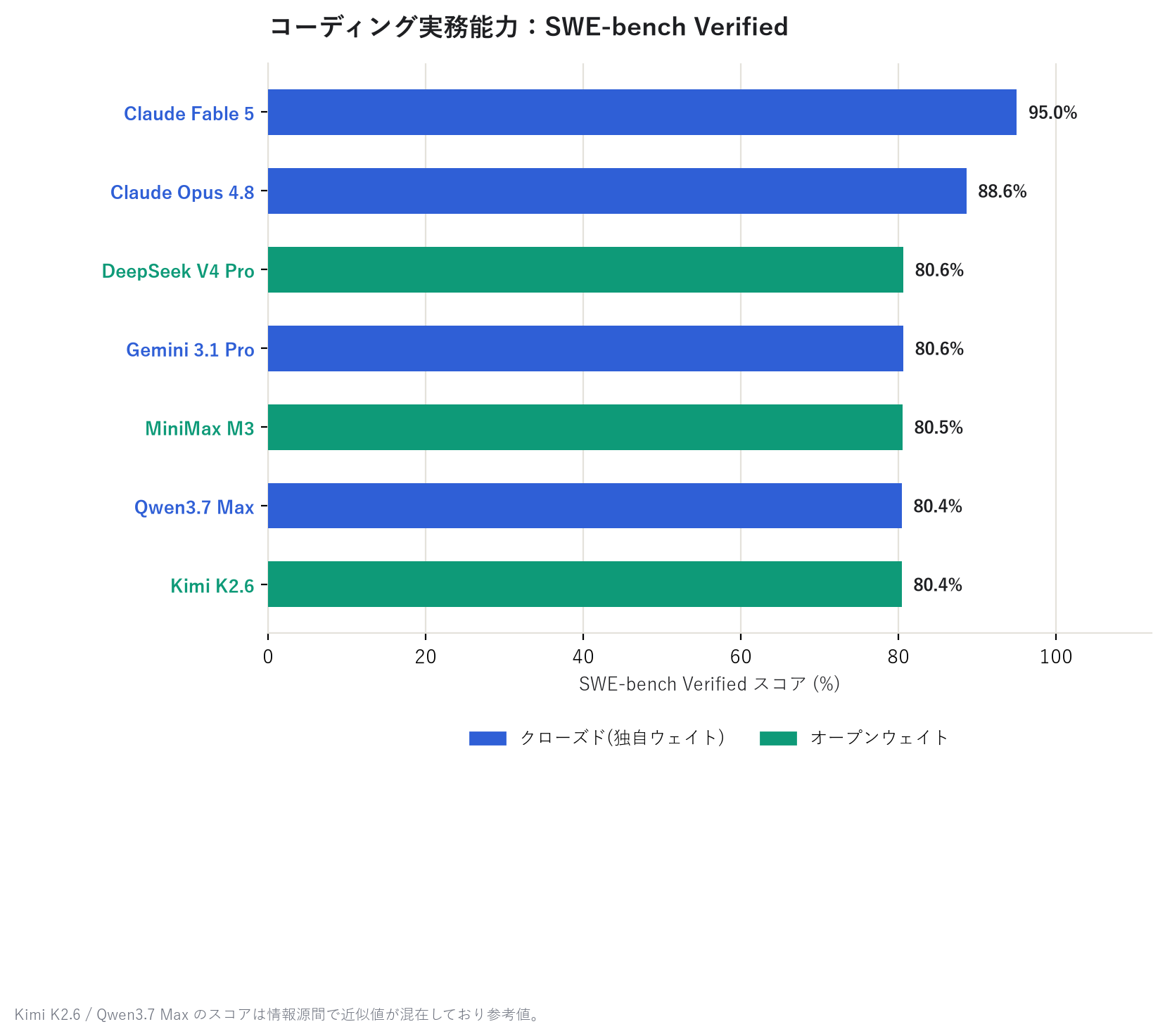
The first chart, "overall capability," is the score from a third-party benchmark organization called the Artificial Analysis Intelligence Index. The second, "coding ability," is the score on SWE-bench Verified, a test that measures how many real-world software bug-fix tasks a model can solve. Both are figures measured and published by independent external evaluation sites, not self-reported by the model vendors.
On overall capability, Claude Fable 5 takes the top spot, about 5 points ahead of GPT-5.5, with Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro close behind. On coding specifically, Claude Fable 5 pulls clearly ahead with a 95% score. Interestingly, right below it, the open-weight DeepSeek V4 Pro holds its own against the closed-model pack.
Bonus: how big are open models "under the hood"
Since open-weight models publish their internals, you can also see their parameter count (the model's size). In the bar charts, the dark green portion is the "activated parameters" actually used during inference, while the light green is the rest of the experts that sit unused at any given moment under the MoE (Mixture of Experts) architecture.
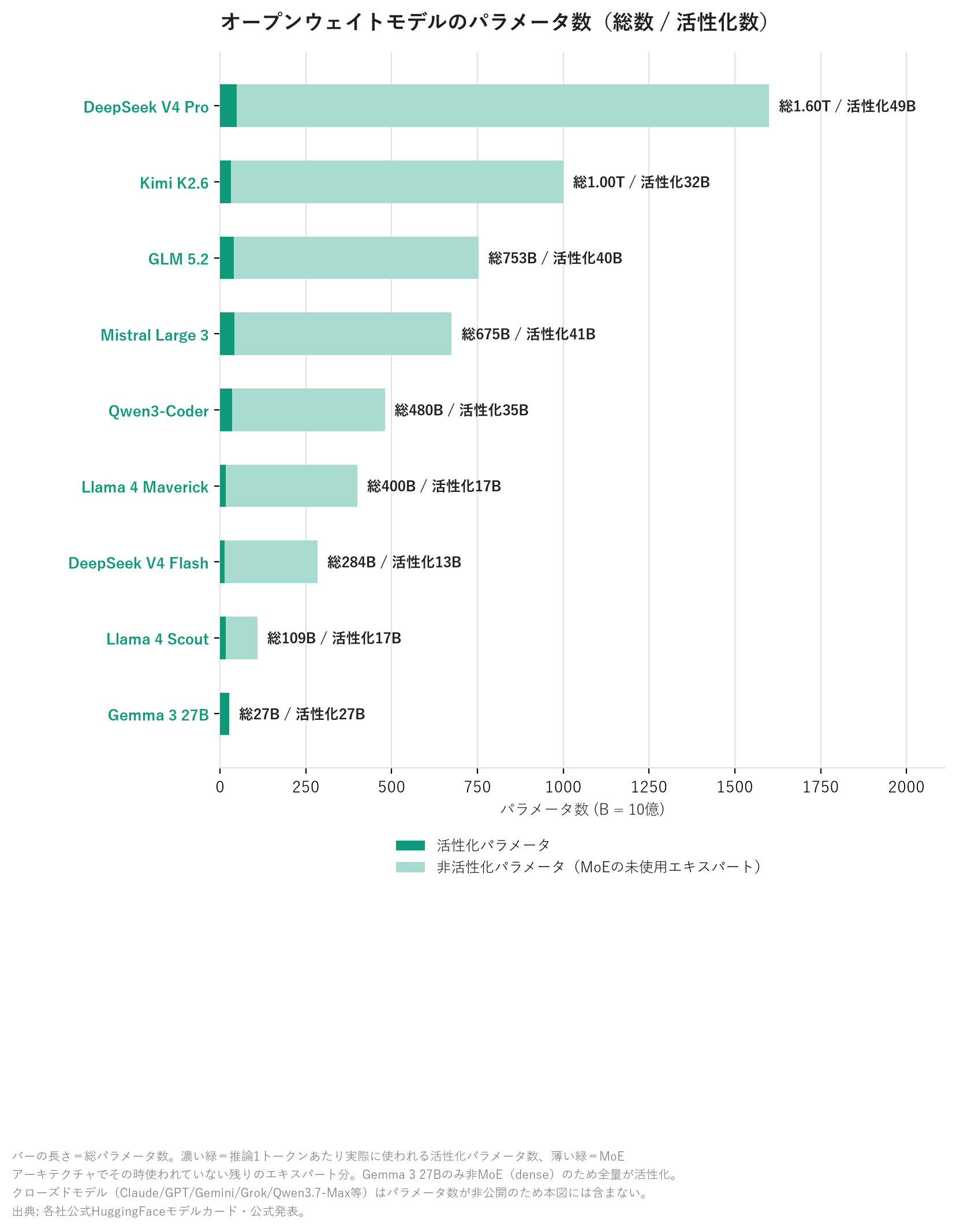
DeepSeek V4 Pro is the largest at 1.6 trillion total parameters, but only 49 billion of those are actually used at inference time (thanks to the MoE mechanism). Being huge while still running light is the whole point. Notably, Gemma 3 27B is the only model in the chart with a fully dark-green bar, because it's not MoE — it's a "dense" architecture that uses all its parameters every time. For dense models, total parameters equal active parameters, so keep in mind that size comparisons against MoE models carry a slightly different meaning.
Conclusion: which one should you pick
- Just want the smartest option available → Claude Fable 5 or Claude Opus 4.8 (brace for the price)
- Cost-efficiency focused, but still want good coding → DeepSeek V4 Pro (dirt cheap yet quite capable)
- A well-balanced everyday model → Claude Sonnet 5 or Gemini 3 Flash
- Want to process huge volumes as cheaply as possible → GPT-5 nano or DeepSeek V4 Flash
Both pricing and rankings move fast in this world, so before you actually use any of these, don't forget to check the latest info at openrouter.ai/models.
Sources for the scores
The benchmark scores used in this post come from the following sources. Both are figures measured and published by third-party evaluation sites independent of the model vendors.
- Overall capability (Intelligence Index): Artificial Analysis
- Coding ability (SWE-bench Verified): SWE-bench Leaderboards (official)
Note that the SWE-bench Verified scores for Kimi K2.6 / Qwen3.7 Max vary somewhat across sources, so they're treated here as reference values only.
Loading...