【2026年7月】生成式 AI 模型比較(Claude、GPT、Gemini、Grok、DeepSeek、Kimi、GLM、Mistral)
透過 OpenRouter,無論是 Claude、GPT、Gemini 這類封閉模型,還是源自中國的開源權重模型, 都能自由切換使用。不過「到底該選哪一個」還是常常讓人猶豫,這次就大致比較了一下主要模型的 價格與實力。
「開源」與「封閉」到底是什麼意思
- 封閉(Closed):像 Claude、GPT、Gemini、Grok 這類模型,其內部(權重)並未公開, 只能透過該公司的伺服器使用。
- 開源權重(Open-weight):像 DeepSeek、Kimi、GLM、Mistral 這類模型,內部是公開的, 任何人都能在自己的電腦或雲端上運行。
依等級劃分的價格
先從最重量級的價格開始看。
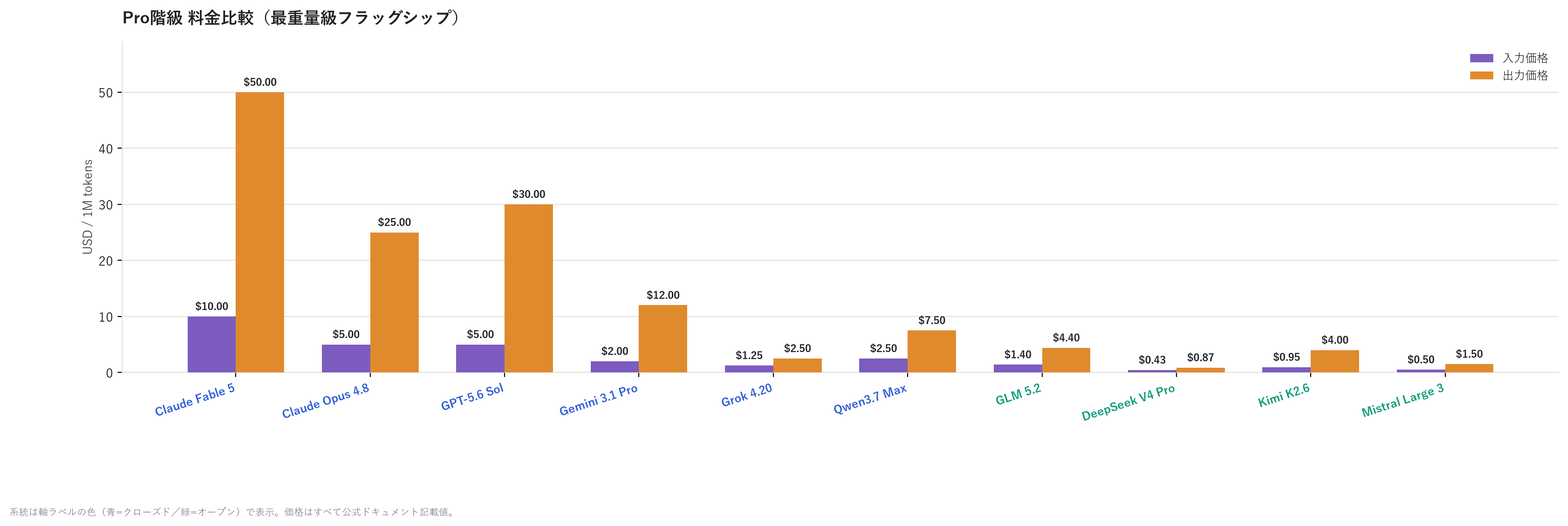
可以看到,Claude Fable 5 貴得驚人(輸出每 1M token $50),而 DeepSeek V4 Pro 的輸出 僅需 $0.87。即使同樣掛著「Pro」的名號,價差竟然超過 50 倍。開源陣營(綠色標籤)全面 偏低價,一目瞭然。
再來看看中量級和輕量級。
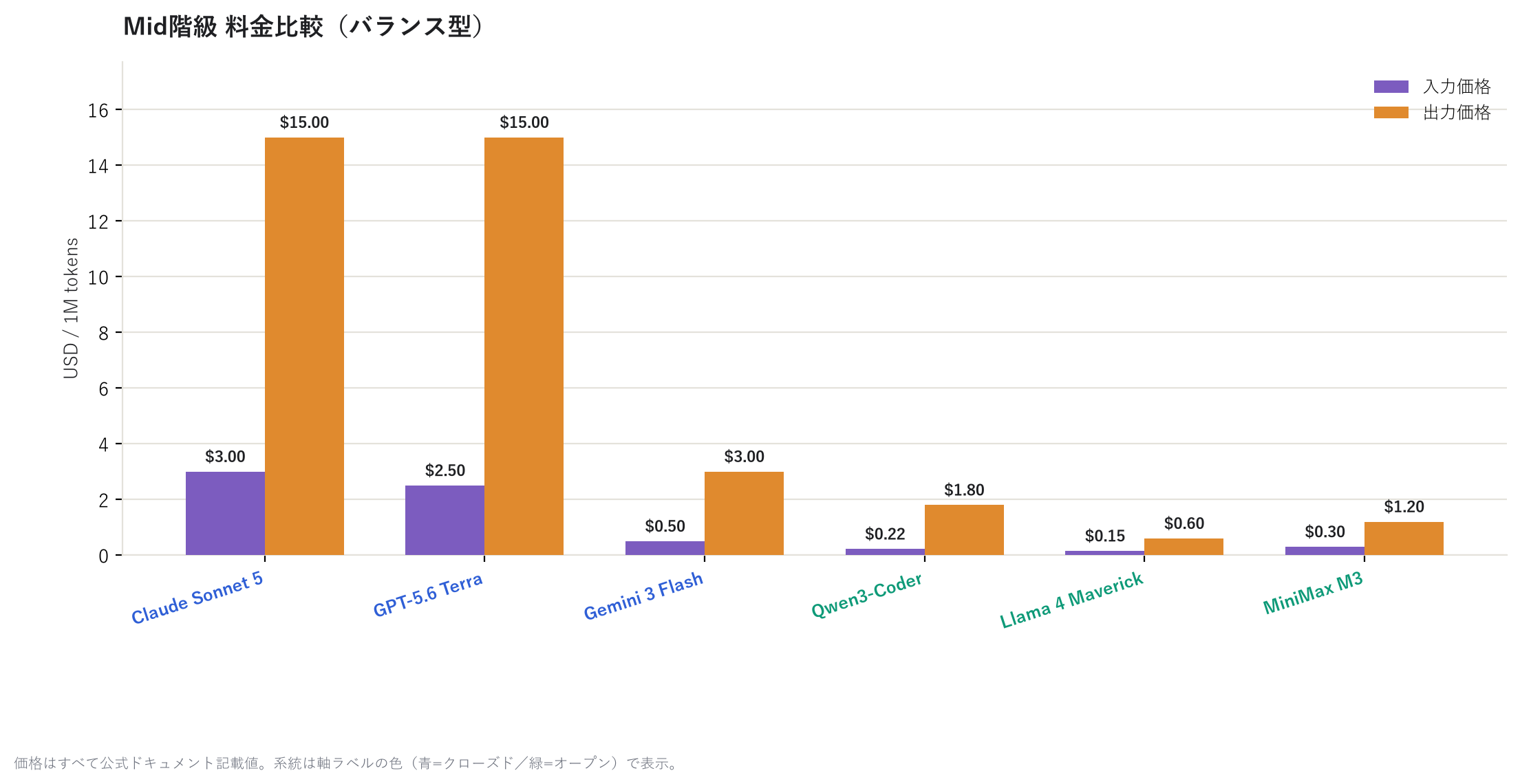
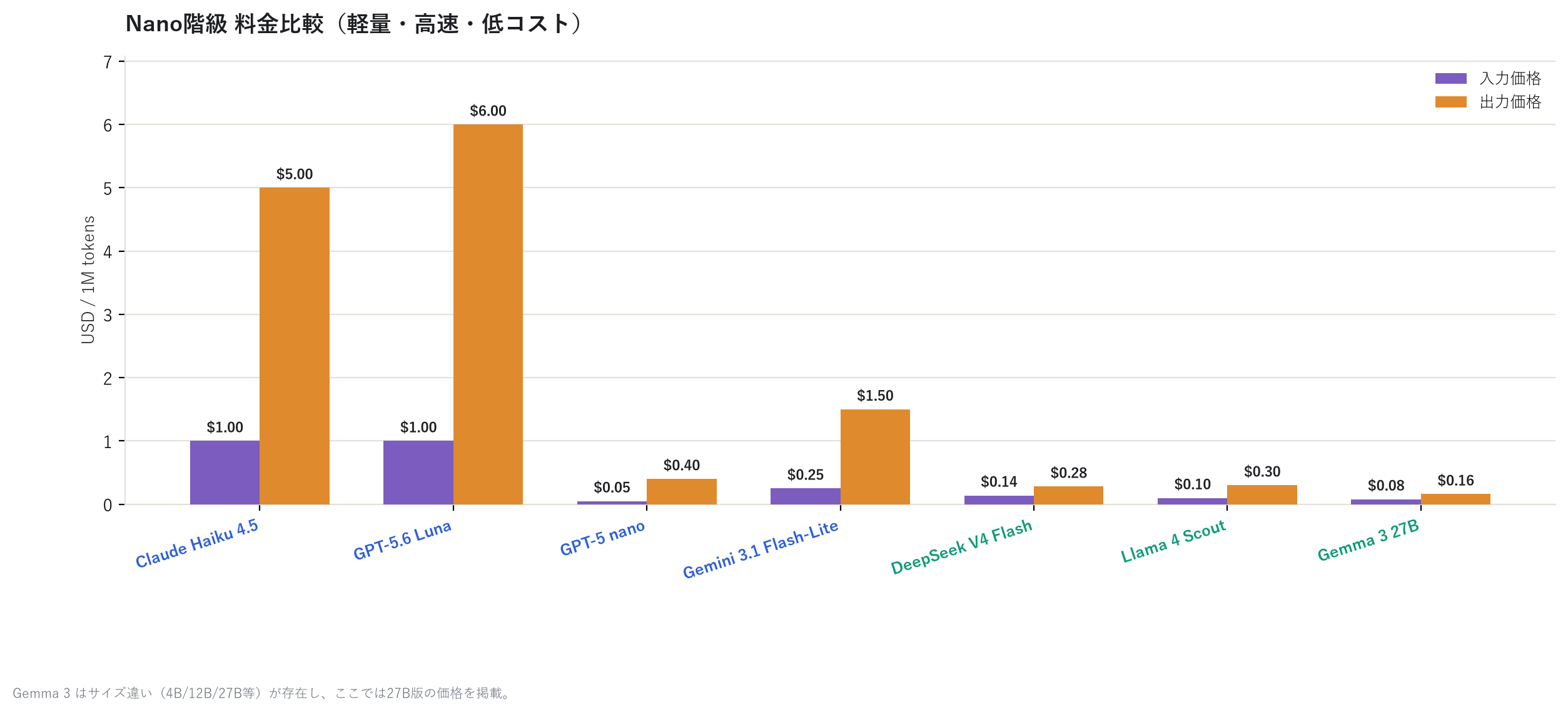
到了輕量級,GPT-5 nano 的輸出價格僅 $0.40,幾乎達到「隨便用」的等級。若只是做簡單的 分類作業或草稿生成,這個等級往往就綽綽有餘。
看看性價比
單看價格,容易讓人覺得「便宜的模型性能應該也差」,但實際上並非如此。這裡先不分等級, 把價格與 Intelligence Index 分數都齊全的 20 個模型彙整成一張圖。盡量涵蓋了 GPT、Gemini、 Qwen、Llama、Gemma、Mistral 等眾多模型,不分開源或封閉。
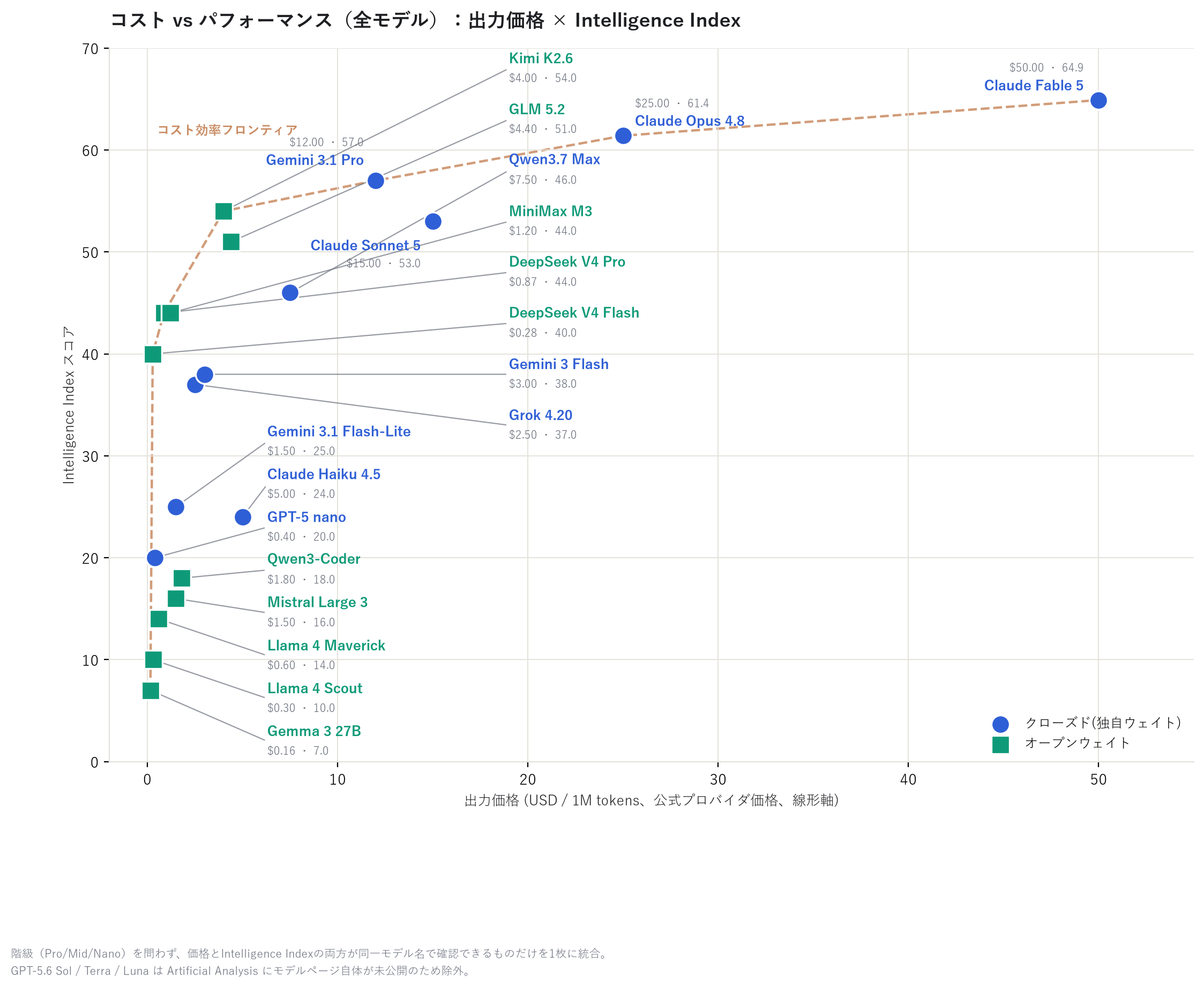
縱軸是「Intelligence Index」這項綜合能力分數(詳見後述)。虛線連接的「性價比前緣」由 跨越 Nano、Mid、Pro 三個等級的 7 個模型構成:Gemma 3 27B → DeepSeek V4 Flash → DeepSeek V4 Pro → Kimi K2.6 → Gemini 3.1 Pro → Claude Opus 4.8 → Claude Fable 5。 DeepSeek V4 Pro 輸出價格僅 $0.87,分數卻逼近 Gemini 3.1 Pro($12.00),實質上已成為 性價比的起點,一枝獨秀。另一方面,位於前緣內側的 Qwen3.7 Max、MiniMax M3、GLM 5.2、 Claude Sonnet 5、Gemini 3 Flash、Grok 4.20、Claude Haiku 4.5、Gemini 3.1 Flash-Lite、 Qwen3-Coder、Mistral Large 3、Llama 4 Maverick、Llama 4 Scout 等模型,相較同價位的其他 模型,實力則略顯遜色。
若重視性價比,不妨先從最便宜的位置開始嘗試。
到底哪個模型最聰明
再來看看綜合能力與程式撰寫能力的排名。
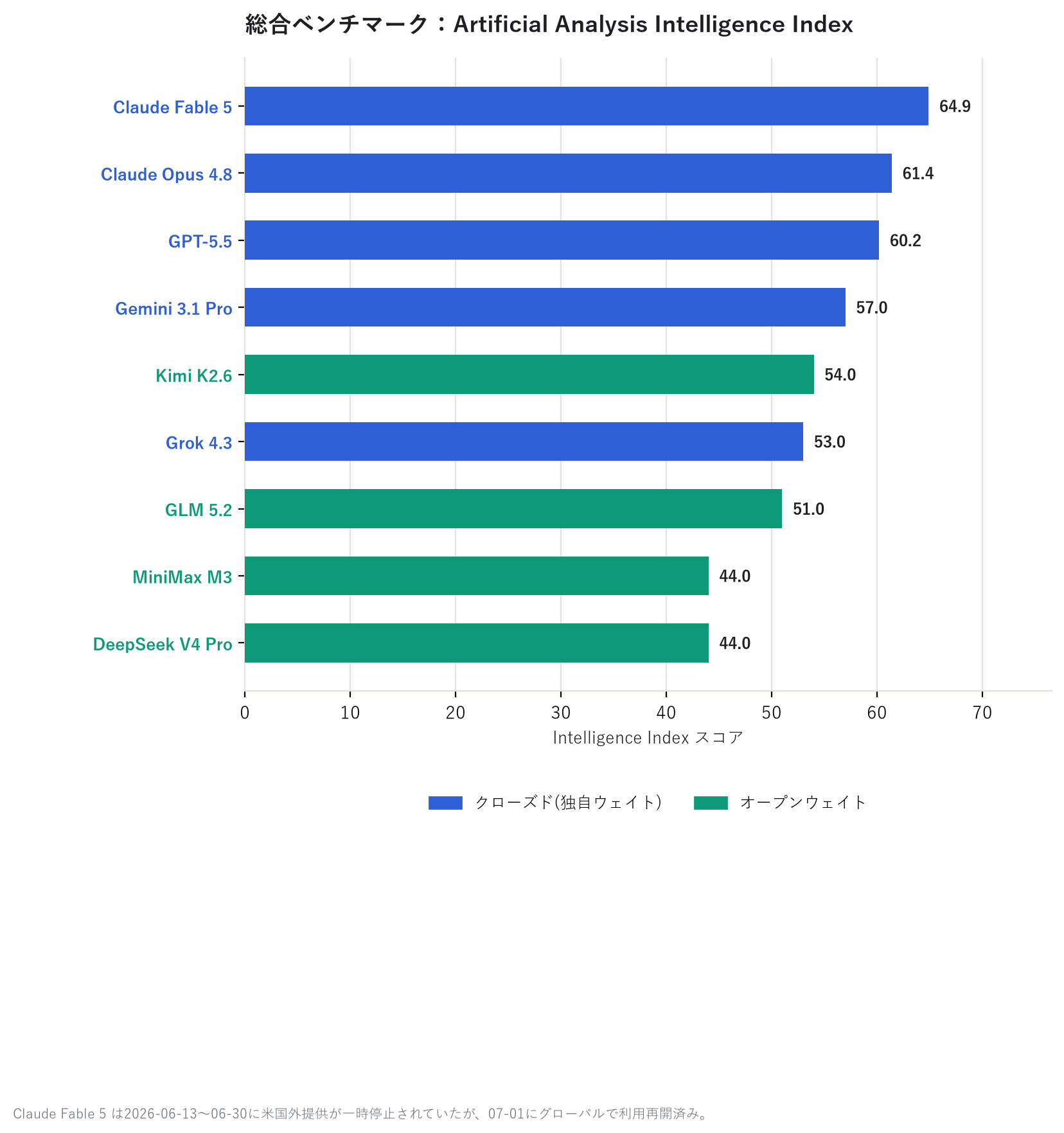
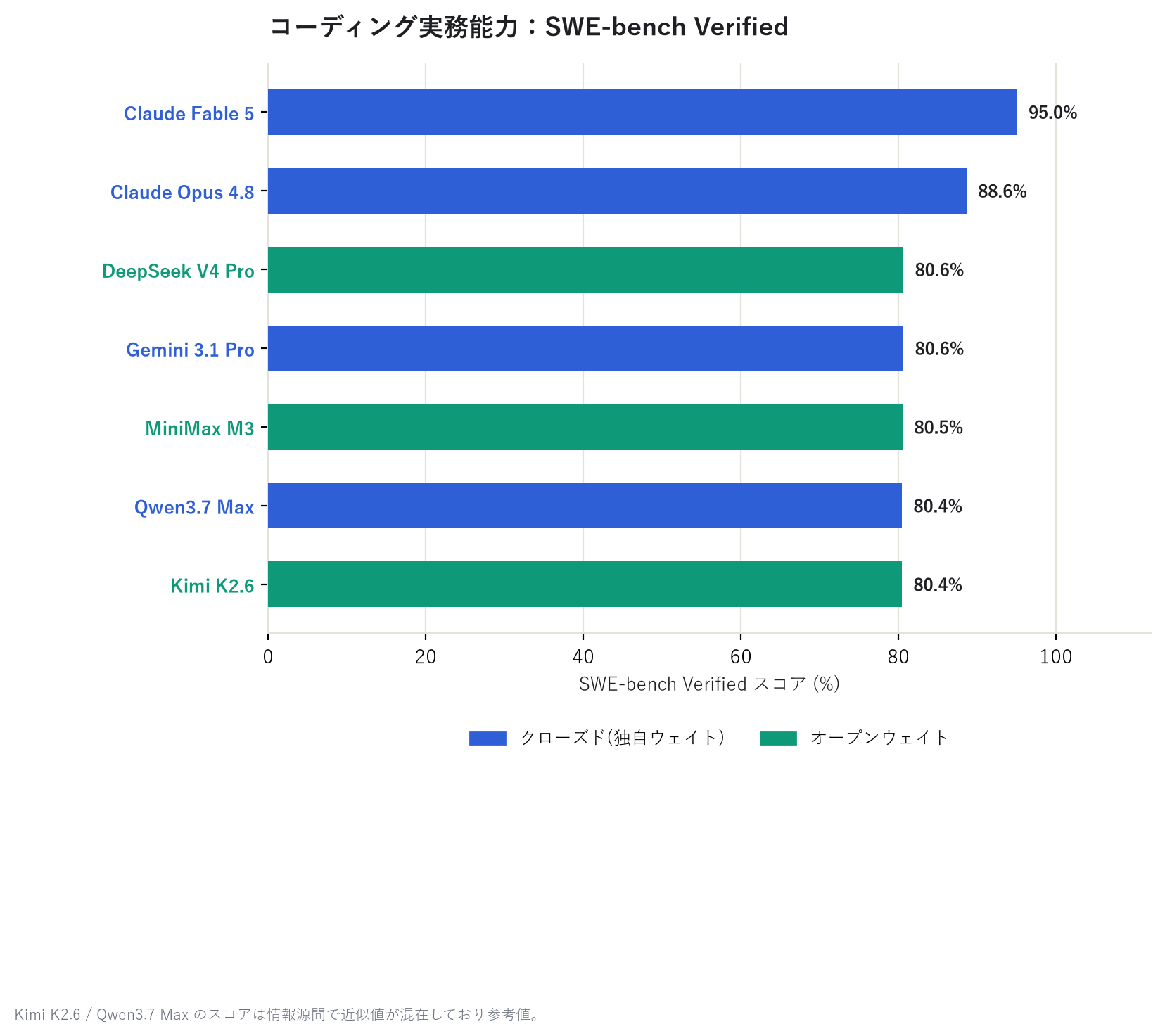
第一張圖的「綜合能力」,是第三方基準測試機構 Artificial Analysis Intelligence Index 的分數;第二張圖的「程式撰寫能力」,是 SWE-bench Verified 的分數,這項測試衡量的是 模型能解決多少實際存在的軟體錯誤修復課題。兩者都不是模型廠商的自我申報,而是由外部評測 網站實際測量並公布的數值。
在綜合能力上,Claude Fable 5 以領先 GPT-5.5 約 5 分的成績奪冠,Claude Opus 4.8、 GPT-5.5、Gemini 3.1 Pro 則以些微差距緊隨其後。僅看程式撰寫能力的話,Claude Fable 5 更是以 95% 的分數一枝獨秀。有趣的是,緊追在後的開源模型 DeepSeek V4 Pro,居然能與 封閉陣營並駕齊驅。
附贈:開源模型「內部規模」有多大
開源權重模型由於內部公開,因此也能得知其參數量(模型規模)。長條圖中深綠色部分是實際 推理時使用的「活性化參數」,淺綠色則是 MoE(Mixture of Experts)架構下,當下未被使用的 其餘專家部分。
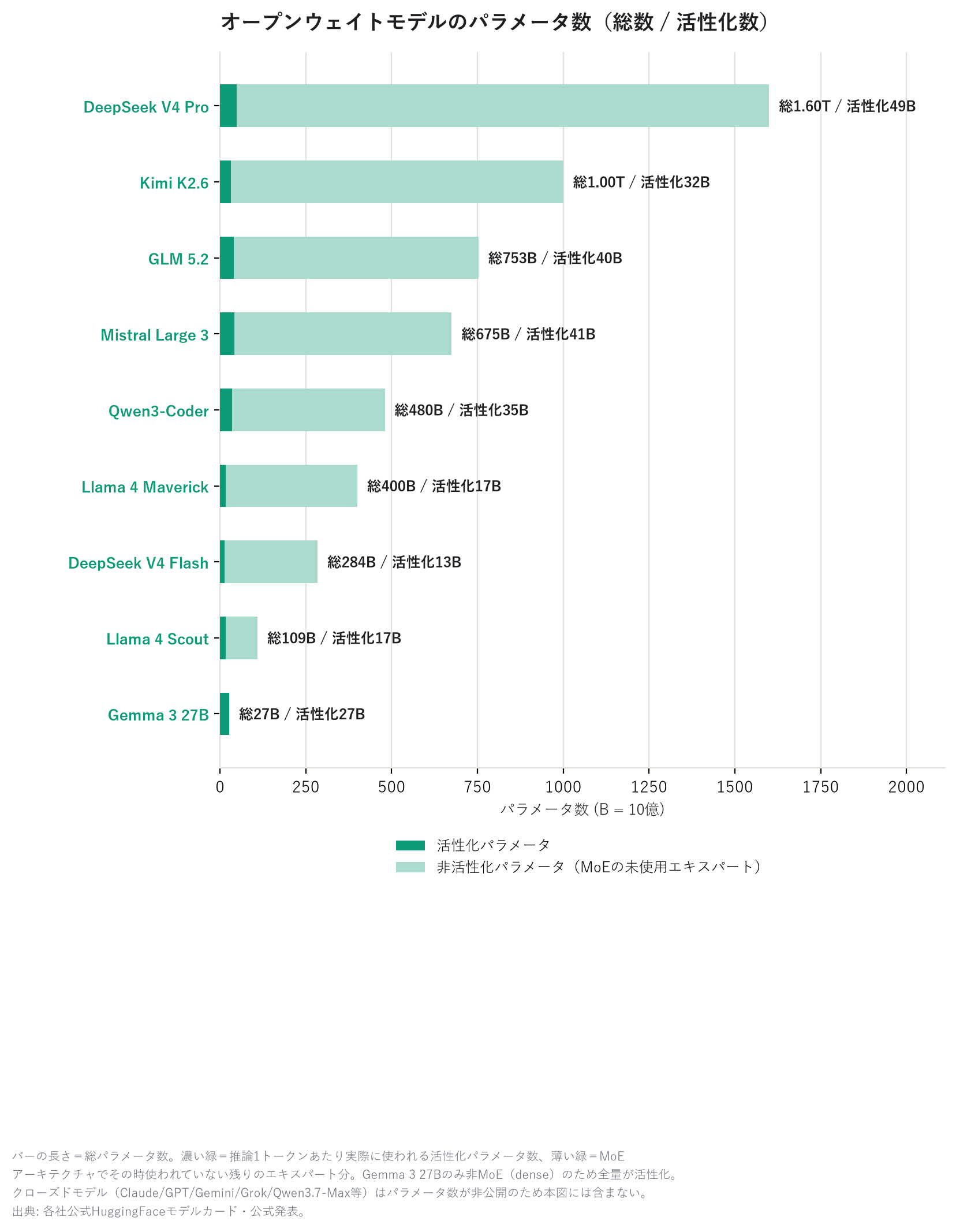
DeepSeek V4 Pro 以總計 1.6 兆參數居冠,但實際運行時只使用其中的 490 億(得益於 MoE 機制)。規模雖大卻能輕快運行,正是重點所在。圖中唯獨 Gemma 3 27B 的長條全為深綠色, 這是因為它並非 MoE,而是每次都會用到全部參數的「dense(密集)」架構。密集模型的總參數量 等於活性化參數量,因此與 MoE 陣營相比,其規模比較的意義略有不同,需特別留意。
結論:該選哪一個
- 不管怎樣就是要最聰明的 → Claude Fable 5 或 Claude Opus 4.8(要有花大錢的心理準備)
- 重視性價比,也想拿來寫程式 → DeepSeek V4 Pro(便宜到不行卻相當優秀)
- 日常使用的均衡型 → Claude Sonnet 5 或 Gemini 3 Flash
- 不管怎樣就是要便宜大量處理 → GPT-5 nano 或 DeepSeek V4 Flash
由於價格與排名的變動速度都很快,實際使用前別忘了到 openrouter.ai/models 確認最新資訊。
分數的資料來源
本文所使用的基準測試分數,來源如下。兩者皆為獨立於模型廠商之外的第三方評測網站所測量並 公布的數值。
- 綜合能力(Intelligence Index):Artificial Analysis
- 程式撰寫能力(SWE-bench Verified):SWE-bench Leaderboards(官方)
另外,Kimi K2.6 / Qwen3.7 Max 的 SWE-bench Verified 分數在不同資料來源間存在近似值混雜的 情形,故僅作為參考值處理。
載入中...