新功能 Amazon S3 Files 讓 S3 桶可以掛載到 EC2
Amazon S3 Files 是一項可以將 S3 桶直接掛載到 EC2 等計算資源的服務,並且以 NFS 檔案系統的形式運行。資料保持在 S3 中,可以使用一般的檔案操作(ls、cp、cat 等)進行讀寫。
S3 Files 是什麼
S3 Files 是基於 Amazon EFS 建立的共享檔案系統,讓使用者能以檔案系統的形式存取 S3 桶中的數據。
主要特點如下:
| 項目 | 內容 |
|---|---|
| 協定 | NFS 4.1 / 4.2 |
| 支援的計算資源 | EC2、Lambda、ECS、EKS |
| 同時連接數量 | 最多 25,000 個計算資源 |
| 讀取吞吐量 | 最大 TB/秒 |
| IOPS | 超過 1,000 萬/桶 |
| 加密 | TLS(傳輸中)+ AWS KMS(儲存時) |
| 檔案系統功能 | POSIX 權限、檔案鎖定、讀取後寫入一致性 |
運作原理
S3 Files 將被訪問的資料自動載入高效能儲存系統,並以低延遲的方式提供服務。
- 小檔案(預設小於 128 KB):直接從高效能儲存中讀取
- 大檔案(1 MB 以上):直接從 S3 流式傳輸
- 寫入:在高效能儲存中寫入後,自動同步到 S3
高效能儲存中的資料,如果在一定時間內(預設 30 天,可設置為 1 - 365 天)未被訪問,將自動刪除。
前提條件
- AWS 帳戶
- EC2 實例(Linux)
- S3 桶(與 EC2 相同區域)
- 兩個 IAM 角色
- 建立檔案系統用:對 S3 桶的讀寫權限
- EC2 實例用:附加
AmazonS3FilesClientFullAccess管理策略
- 安全群組:允許 NFS 的 2049 端口通訊
IAM 角色的建立
S3 Files 需要兩個 IAM 角色。
1. 用於建立檔案系統的角色
使用管理控制台時會自動創建,因此不需要手動創建
此角色用於讓 S3 Files 存取桶。
# 創建角色
aws iam create-role \
--role-name S3Files-FileSystem-Role \
--assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": { "Service": "s3files.amazonaws.com" },
"Action": "sts:AssumeRole"
}
]
}'
# 附加 S3 Files 客戶端策略
aws iam attach-role-policy \
--role-name S3Files-FileSystem-Role \
--policy-arn arn:aws:iam::aws:policy/AmazonS3FilesClientFullAccess
在創建檔案系統時用 --role-arn 指定此角色。
2. 用於 EC2 實例的角色
未附加 IAM 角色會導致掛載失敗
在 CloudShell 中創建以下角色。
# 創建角色
aws iam create-role \
--role-name EC2-S3Files-Role \
--assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": { "Service": "ec2.amazonaws.com" },
"Action": "sts:AssumeRole"
}
]
}'
# 附加 S3 Files 客戶端策略
aws iam attach-role-policy \
--role-name EC2-S3Files-Role \
--policy-arn arn:aws:iam::aws:policy/AmazonS3FilesClientFullAccess
# 創建並附加實例檔案配置
aws iam create-instance-profile \
--instance-profile-name EC2-S3Files-Profile
aws iam add-role-to-instance-profile \
--instance-profile-name EC2-S3Files-Profile \
--role-name EC2-S3Files-Role
將此角色附加到實例上。
設定步驟
1. 準備 S3 桶
在 S3 控制台中創建通用桶,也可以使用現有的桶。
需要特別注意的是,必須啟用桶的版本控制設定
2. 創建檔案系統
從控制台創建
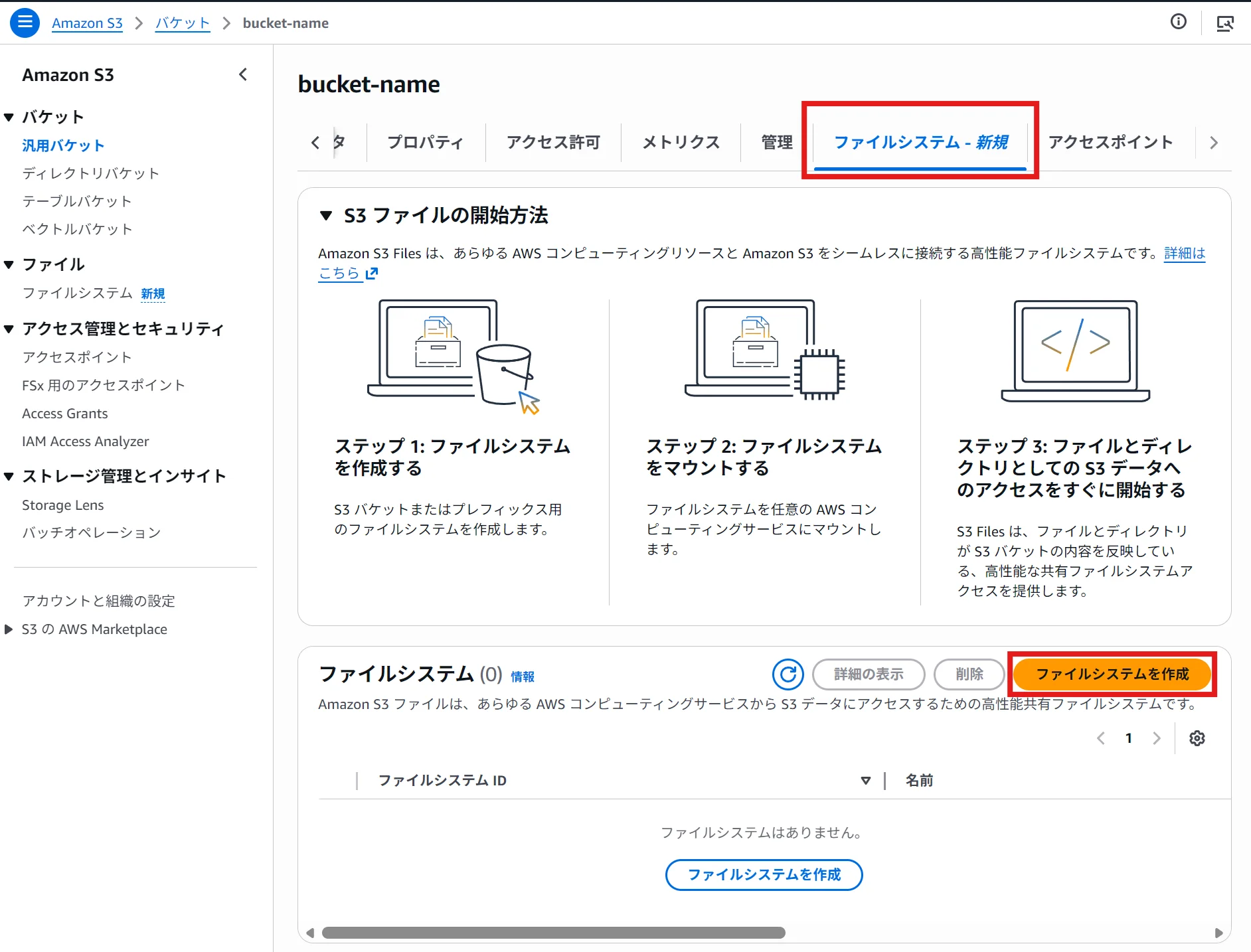
- 在 S3 控制台中選擇桶
- 點擊「檔案系統」標籤 → 「創建檔案系統」
從控制台創建後,所有可用區會自動創建掛載目標和存取點。
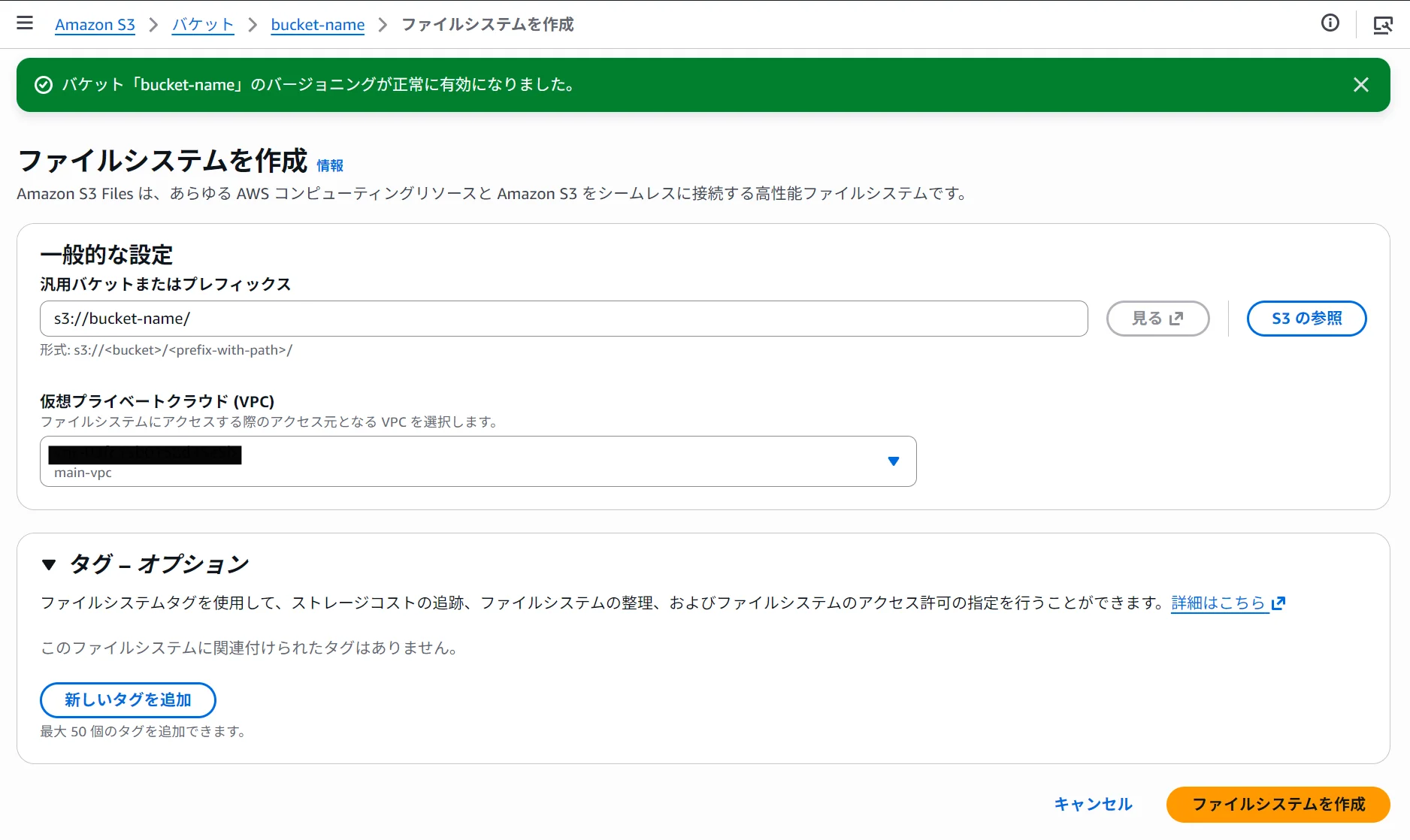
- 指定前綴和 VPC,然後點擊「創建檔案系統」。
記錄下輸出的檔案系統 ID(例如:fs-0123456789abcdef0)。
3. 在實例中掛載
在終端中執行以下命令。
# 創建掛載點
sudo mkdir /mnt/s3files
# 挂載
sudo mount -t s3files fs-0123456789abcdef0:/ /mnt/s3files
如果無法掛載,請執行以下命令再試一次:
sudo dnf install -y amazon-efs-utils # Amazon Linux, RHEL
# sudo apt install -y amazon-efs-utils (Ubuntu, Debian)
如果在執行 dnf 命令時通訊出現問題,請設置 S3 端點(網關),並指定與實例相同的可用區。
但要注意,S3 端點的路由表應與實例所在的子網相同。
確認掛載情況:
df -h /mnt/s3files
應顯示類似以下內容:
Filesystem Size Used Avail Use% Mounted on
<s3files-dns> 8.0E 129M 8.0E 1% /mnt/s3files
4. 確認運行
cd /mnt/s3files
# 創建檔案
sudo sh -c 'echo "Hello, s3 Files!" > test.txt'
# 讀取檔案
cat test.txt
# 創建目錄
sudo mkdir test-directory
ls -la
# 複製檔案
sudo cp test.txt test-directory/
cd test-directory/
# 確認檔案列表
ls -la
寫入的檔案會在約 1 分鐘內與 S3 桶同步。可以在 S3 控制台確認對象已創建。
aws s3 ls s3://<bucket-name>/
自動掛載設定
為了在重啟後保持掛載,需要將以下內容添加到 /etc/fstab。
# 添加到 /etc/fstab
fs-0123456789abcdef0:/ /mnt/s3files s3files _netdev,nofail 0 0
_netdev 是一個選項,確保在網路連接後再進行掛載,這是必需的。加入 nofail 可以防止掛載失敗時導致實例無法啟動。
收費
S3 Files 的收費如下:
- 高效能儲存使用量:檔案系統中數據的儲存費用
- 檔案系統存取費用:對高效能儲存進行讀寫操作的費用
- S3 請求費用:對於直接從 S3 讀取大於 1 MB 的檔案,僅收取 S3 GET 費用
為按量計費的無需配置模式,根據 AWS 的說法,與傳統 S3 和檔案系統間數據複製相比可減少最多 90% 的成本。
總結
- 使用 S3 Files 可以將 S3 桶掛載為 NFS 檔案系統在 EC2 上
- 數據保留在 S3 中,可以使用
ls、cat、cp等正常的檔案操作 - 透過高效能儲存提供低延遲,未被訪問的數據會自動退避
- 通過
/etc/fstab設定自動掛載,即使重啟後也能維持